
G検定の学習として、今回は今まで書いてきた基礎をベースとしたいろいろな研究分野を勉強していきます。
昨日G検定を受けて、そこで感じたことを反映させながら紹介していきます。
ディープラーニング:画像認識分野
AlexNet
AlexNetは、2012年のILSVRC(イメージネット画像認識コンテスト)で従来手法のサポートベクターマシンにかわって、ディープラーニングに基づくモデルとして初めて優勝したものです。
開発の筆頭は、Alex Krizhevsky(アレックス・クリジェフスキー)で、AlexNet。特徴は、ReLU、SRN、データ拡張、2枚のGPUの利用。
2012年のAlexNetは実用性を兼ね備え、一世を風靡しました。私も出張中に海外の研究者から、ニューラルネットが現状の最高の精度を出していると聞きジョークなのかと疑ったものでした。
AlexNetは様々な特徴があります。
・活性化関数ReLU
歴史をたどってディープラーニングを学ぶ 第二回 AlexNetとReLU
・Max Pooling
・GPUの活用
・Data Augmentation
・Dropout

AlexNetの登場でILSVRC(イメージネット画像認識コンテスト)は、1000カテゴリンお画像分野を拡張して一般の画像認識への道が模索されるように成りました。
この方向性の1つが、R-CNNです。
R-CNN (Regional CNN):従来の物体検出モデルをCNNに置き換えたもの
ILSVRC(イメージネット画像認識コンテスト)では、以下の2つの課題があります。
- 位置課題(Location Task)・・・どこに
- 検出課題(Detection Task)・・・何が
R-CNN(Regional CNN)は、画像全体から特徴量を抽出させるCNNにRegion(領域)ごとの特徴を抽出して、人間が行っている物体認識を行う技術です。
自動運転で物体認識を行ったり、とある画像を文章化したりするときに使われています。
Regionと言っているのをもう少し詳しく言うと、関心領域(Region of Interest)の切り出しを行い、その領域毎に個別にCNNを呼び出して特徴量を抽出するという2段階の手法です。
この関心領域の切り出しというのは、画像上の矩形領域(長方形)の左上の座標と右下の座標で表現することにすれば、4つの点を予測する回帰問題とみなすことができます。
この矩形領域のことを、バウンディングボックス(Bounding Box)と呼びます。
CNNは、畳み込み演算を多層で繰り返すので、
各層の個々のニューロンは、カーネルの大きさ分だけしか下位層から入力を受け取らないことになりますので、
CNNは入力画像中の位置情報を表現している = 関心領域を切り出すための情報が含まれている
と言えるのです。
これにより、領域の切り出し + 切り出した領域の物体認識を同時に行うことができるようになり、これを高速RCNN(Fast RCNN)と呼びます。
F-RCNNでは画像認識を行う時には毎回CNNを走らせる必要はなく、RegionProposalの抽出した特徴領域を切り出し、全結合層に与えるだけでよい。
最新のRegion CNN(R-CNN)を用いた物体検出入門 ~物体検出とは? R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN~
従来のR-CNNが画像認識毎にCNN層も走らせていたのに比べると大幅な高速化を達成できる。
Fast RCNNを改良された、Faster RCNNも提案され、これらによりほぼ実時間で、関心領域からの切り出しと認識ができるようになりました。(スゴイ)
これで、動画認識へCNNを応用できるようになっていきます。
まだまだ発展形で、
YOLO(You Only Live Once:1度だけしか見ない)とSSD(Single Shot Detector:1ショット検出器)というモデルが提唱されています。
セマンティックセグメンテーション、インスタンスセグメンテーション
セマンティックセグメンテーション(Semantic Segmentation)
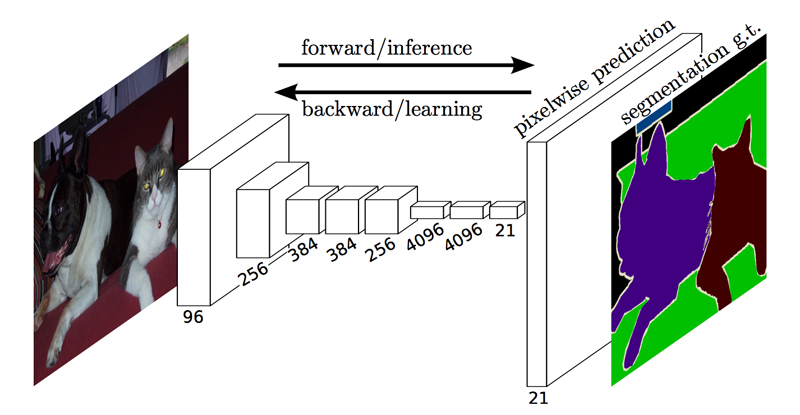
セマンティックセグメンテーションは、R-CNNのような矩形の領域を切り出す方法ではなく、より詳細な領域分割をするモデルです。
そのため、物体認識においては、
領域分割を繊細に行う必要があります。
そのため、
入力画像のどの位置に物体が存在するのかを画素単位で指定することができれば認識精度も向上できると言えます。
セマンティックセグメンテーションを実現するネットワークをとして、
完全畳み込みネットワーク(Fully Convolutional Network, FCN)があります。
これは、すべての層が畳み込み層であるモデルになります。
つまり、
各画素がそれぞれどのカテゴリに属するのかを出力する必要があるため、
出力層には、縦画素数 × 横画素数 × カテゴリ数
の出力ニューロンが用意されます。
普通のCNNは、
「出力層のユニット数」が識別するべきカテゴリ数でしたが、
FCNは、入力画像の画素数だけ出力層が必要になります。
CNNでは、畳み込み演算によって、畳み込みのカーネル幅(受容野)だけ近傍の入力刺激を加えて計算することになるため、
上位層では下位層に比べて受容野が大きくなり、その影響で画像サイズは小さく・粗くなりますので、
最終出力層に入力層と同じ解像度の画素数を得るためには、
畳み込みと反対方向の解像度を細かくする工夫が必要ということになります。
粗くなっちゃったのを戻してあげる工夫が必要ということですね!
これを解決する方法の1つは、
アンサンプリング(Unsampling)で、下位のプーリング層の情報を用いて、詳細な解像度を得ることができます。
畳み込み層の上位層では解像度が粗くなるところを階層のプーリング情報を使ってアンサンプリングすることで解像度を復元するということです。
同じような仕組みが、セグネット(Segnet)というものでも実現できます。
こちらは、下位のプーリング層の情報を用いることで領域分けを行うものです。
まとめると、
バウンディングボックスは、矩形(四角形)の領域を切り出してその切り出した領域内の物体識別を行うことです。
セマンティックセグメンテーションは、各画素がどのカテゴリに属するのかを求める方法です。
そして、個々の物体毎に認識させることをインスタンスセグメンテーションといいます。
ディープラーニング:自然言語処理分野
単語の意味を表現できるベクトル空間モデルのワードツーベック(Word2vec)と、その周辺、そしてニューラル画像脚注付け、ニューラルチューリングマシンについて。
word2vec(単語の意味を表すベクトル空間モデル)
文章中の単語(word)は、記号の集まり(文字列)として表現する事ができるものを、
word2vecでは、記号をベクトルとして表現することでベクトル間の距離や関係として単語の意味を表現しようとするモデルです。
ベクトル空間モデル(Vector Space Models)
単語埋め込みモデル(Word Embedding Models)・・・単語の意味をベクトル空間の中に表現したと考えて
とも呼ばれます。

word2vecには、スキップグラム(Skip-gram)と、CBOWの2つの手法があります。
スキップグラムは、ある単語を与えて、周辺の単語を予測するモデルになります。
CBOWは、スキップグラムの逆で、周辺の単語を与えてある単語を予測するモデルです。
word2vecの単語埋め込みモデルは、爆発的に発展したため、
自然言語処理(Natural Langage Processing, NLP)の基礎と考えることができます。

fastText
2013年にword2vecを提案したトマス・ミコロフらにより開発されたモデルです。
変更点は、単語の表現に文字の情報も含めることです。
これにより、訓練データには存在しない単語(Out of Vocabulary)を表現できるようになりました。
また、fastTextは、学習に要する時間が短いという特徴もあります。
ELMo(Embedding Language Modeling)
アレンインスティチュートによって開発された、文章表現を得るモデルです。
2層の双方向リカレントネットワーク言語モデルの内部状態から計算されます。fastText同様、訓練データには存在しない単語(Out of Vocabulary)を表現できるようになります。
言語モデルにおいては、各層は単語に関する異なる種類の情報を符号化すると考えます。

マルチタスク言語モデル
fastTextとELMoは文章表現は、単語埋め込みモデルで得られた単語表現の平均を用います。
マルチタスク言語モデルは、以下などを行うことができる文章ベクトルモデルのことです。
- 次文あるいは前文予測
- 機械翻訳
- 構文解析
- 自然言語処理
1対多のマルチタスク学習により、複数課題間に共通の普遍的な文章埋め込み表現を学習させた、普遍埋め込みモデル(Universal Embedding)と呼ばれます。
画像脚注付け
画像認識を実行するCNNと、言語モデル(Language Model, LM)としてリカレントニューラルネットワークを組み合わせると、
ニューラル画像脚注付け(Neural Image Captioning, NIC)になります。
NICは、
CNNの最終そうの出力を使うのではなく、全結合層の直下、すなわち畳み込み層の最上位層をリカレントニューラルネットワークで構成される文章生成のネットワークの入力とすることです。
ニューラルチューリングマシン
ニューラルチューリングマシン(Neural Turing Machines, NTM)は、
チューリングマシンをニューラルネットワークにより実現する試みです。
メモリと入呂つ力との間にあるコントローラーに使われているLSTMで、
系列制御、時系列処理に加えて複雑な問題を解くことができます。
ディープラーニング:音声認識分野
WaveNetは、音声合成と音声認識の2つを行うことができるモデルです。2016年にDeepMind社から発表されました。


ディープラーニング:強化学習分野
強化学習(Reinforcement Learning)の応用は、
アタリのゲームに対して応用したDQN(Deep Q Networks)以来、たくさん夜に出てきました。
アルファ碁は、後番の状況認識にCNNを使い、次の手の選択にモンテカルロ木探索を使って効果を出しました。
強化学習の改善方法
- 方策(ポリシー)ベース(Value Function Base)
- 行動価値関数ベース(Q Function Base)
- モデルベース(Model Base)
この3つが強化学習の改善手法です。
過去の名人戦の棋譜の学習ではなく、0からセルフプレイが学習を進めたアルファ碁ゼロは遥かにアルファ碁を凌駕しました。

