こんにちは!ともわん(@TomoOne4)です。
データ分析は僕のようなマーケティング分野の人間にもかなり使える技術となりました。
今回は、Pythonでデータ分析を行う際に習得必須な
・Numpy
・Pandas
・Matplotlib
・Seaborn
の概要をお伝えしていきます。
Pythonでのデータ分析で必要なライブラリ(最低限)
Pythonは本当に様々な事ができるプログラム言語です。
・Webアプリの開発
・データ分析(データサイエンス)
・自動化
Webアプリの開発は、Ruby on RailsやPHPのLaravelなどで作られることも多いですが、
Pythonでも、DjangoやFlaskなどのフレームワークが超有名なため、これらを使うことで効率的に開発することも可能です。
僕はアプリ開発はあまりまだやっていません。
データ分析(データサイエンス)分野は、僕が1番フォーカスしている分野です。
大量のデータから本質を見つけ出すために計算・ビジュアライズ・機械学習による予測などもできてしまいます。
自動化分野も注目しています。
分かりやすいところだと、Excelを自動で動かしたり、Webページから必要な情報を取得してくるスクレイピングを行ったりできるため、リスト作成や分析用のデータを集めるという意味でも重宝します。
Pythonは、非常に多くのライブラリが用意されており、そのライブラリを駆使して分析や開発を行っていきます。
データ分析のためのライブラリで必須のものを紹介していきます。
Numpy(ナムパイ)
Numpy(Numerical Python)は、科学や数学のための数値計算を行うライブラリです。
無料で利用可能です。
特徴:
・計算を行う処理(つまりあらゆるもの)に使える
・PandasやMatplotlib、Scikit-learn(機械学習のライブラリ)では必須
・多次元配列を作り、操作できる(ベクトルや行列)
実際にやってみます。
# Numpyをインポート
import numpy as np
# ベクトルを作成
vector = np.array([1, 2, 3])
print(vector)
vector▼出力
[1 2 3]
array([1, 2, 3])# 行列を作成
matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(matrix)
matrix▼出力
[[1 2 3]
[4 5 6]
[7 8 9]]
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])matrix.shape▼出力
(3, 3)このように、matrixは3行3列の行列を簡単に作ることができます。
# 0から5個を取得
np.arange(5) ▼出力
array([0, 1, 2, 3, 4])
Pandas
Pandas(パンダス)は、データの読み込み、統計量(平均や標準偏差など)の計算と表示、データ表のカスタマイズといった事ができます。
無料で利用できます。
特徴:
・データ分析をする前にデータをきれいにしたり望ましいデータだけを抽出したりする時に重宝
・SeriesとDataFrameという表が便利
実際にやってみます。
# Pandasをインポート
import pandas as pd
# Pandasに必要なNumpyもインポート
import numpy as np
# NumpyからDataFrameを作って表示してみる
## 0〜9までの10個の数字を2行5列の行列にして 変数ndarrayに代入
ndarray = np.arange(0, 10).reshape(2, 5)
## ndarrayを見てみる
ndarray▼出力
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])2行5列の行列で0〜9までの数字がarrayになっています。
## DataFrameで表示
pd.DataFrame(ndarray)▼出力
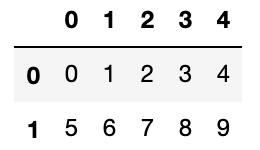
データが表のようになっているのがわかります。
# CSVの読み込み
## 動作させる.py, .ipynbと同階層にCSVファイルがあるとし、サンプルのCSVを読み込んでみる。
df = pd.read_csv('test-data.csv')
## 変数dfを表示
df▼出力

こんな感じでCSVを読み込んで表示させることができました。pd.read_csv(‘CSVファイル名’)でファイルを読み込めるので、かなりシンプルです。
※ちなみにこのテストデータは、以下のサービスを使って自動生成させたものです。

## 数値項目(今回は"選んだ数字")の統計量を確認
df.describe()▼出力
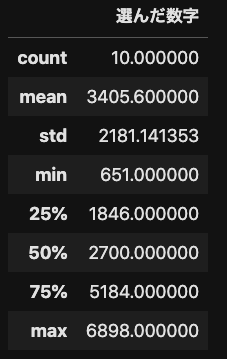
統計量が計算され、表にしてくれました。
countはデータの個数
meanは算術平均
stdは標準偏差
minは最小値
25%は1/4分位数
50%は中央値(median)
75%は3/4分位数
maxは最大値
Matplotlib
Matplotlibは、グラフを描画したりビジュアライズができるライブラリです。もちろん無料で使え、Matplotlibを使ってグラフを描画すると「すげぇ」と思うはずです。
特徴:
・棒グラフ、円グラフ、散布図など様々なグラフの描画ができる
・データの可視化をしたものを資料として使うことができる
・グラフの装飾なども簡単にできる
実際にやってみます。
# Matplotlibをインポート
import matplotlib.pyplot as plt
%matplotlib inline
# 必要なライブラリもインポート
import numpy as np
import pandas as pd
## リストを用意して、描画させる
x = [1, 2, 3, 4, 5]
y = np.array(x) ** 2
plt.plot(x, y)▼出力
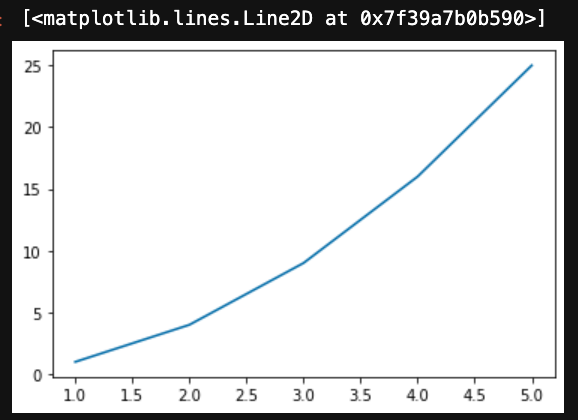
これだけで、表が作成できました。
## PandasのDataFrameを使ってみる
df = pd.DataFrame({'apple': [1, 2, 3, 4, 5, 6],
'banana': [10, 15, 40, 100, 200, 400]})
plt.plot('apple', 'banana', data=df)
## タイトル
plt.title('TEST GRAPH')▼出力
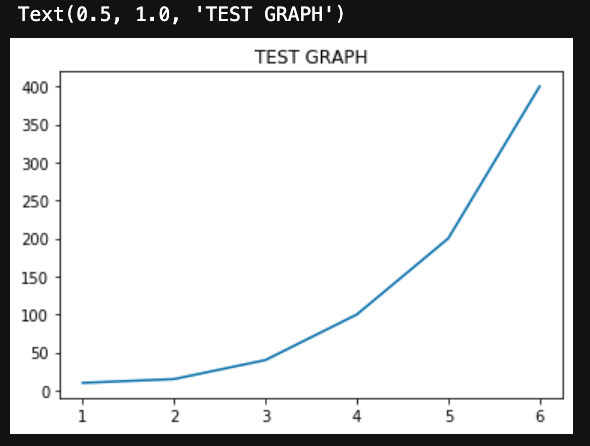
PandasのDataFrameでも簡単に描画ができます。タイトルもつけてみました。
# 生年月日から、年の4桁を取り出し
df['年'] = df['生年月日'].apply(lambda x: int(x[:4]))
# 年と合計得点で棒グラフを表示(透過率を設定 alpha=0.2)
plt.bar(df['年'], df['合計得点'], alpha=0.2)
# ラベルを付ける
plt.xlabel('Birth')
plt.ylabel('Total Score')
plt.title('Birth year and Total score')▼出力
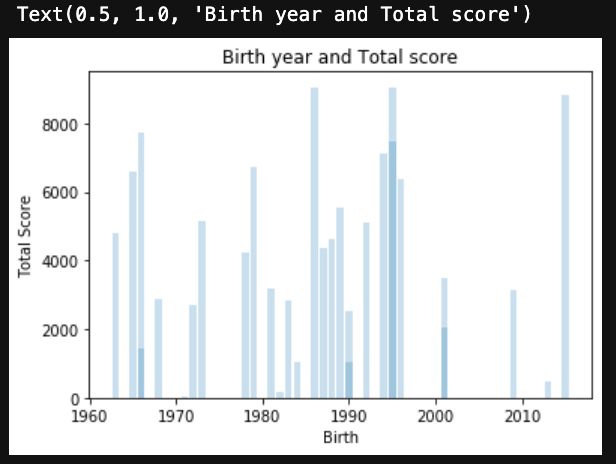
タイトルに加えてx軸とy軸にラベルを付けて、棒グラフ(bar)で描画させてみました。透過率(alpha)を調整して、重なっているデータもわかりやすくしています。
Seaborn
Seaborn(シーボーン)は、Matplotlibと同じくグラフなどを描画できるビジュアライズのためのライブラリです。Matplotlibよりもきれいなデザインが出せます。無料です。
特徴:
・Matplotlibよりかっこいいグラフが簡単に作れる
・内部では、Matplotlibが動いている
試しにやってみます。
# seabornをインポート
import seaborn as sns
%matplotlib inline
# その他必要なライブラリをインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 生年月日から、年の4桁を取り出し
df['年'] = df['生年月日'].apply(lambda x: int(x[:4]))
# 年と合計得点で棒グラフを表示(透過率を設定 alpha=0.2)
sns.distplot(df['年'])
# ラベルを付ける
plt.xlabel('Birth')
plt.ylabel('Total Score')
plt.title('Birth year')▼出力
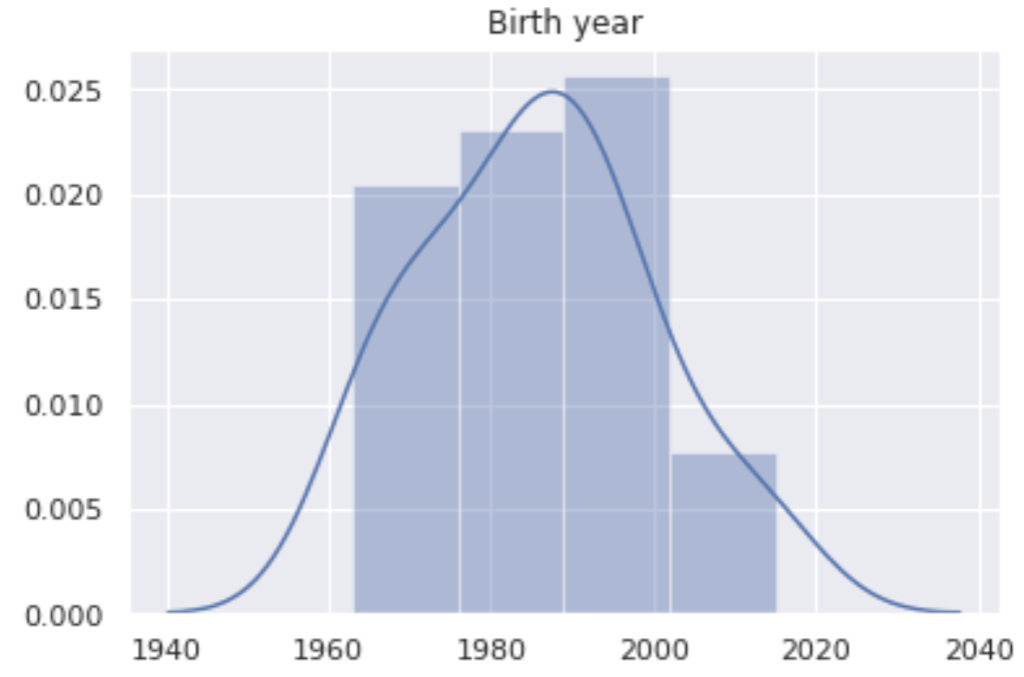
Matplotlibよりもビジュアライズされたグラフになりました。
# DataFrameの全ての数値カラムでpairplotを作る
sns.pairplot(df)▼出力
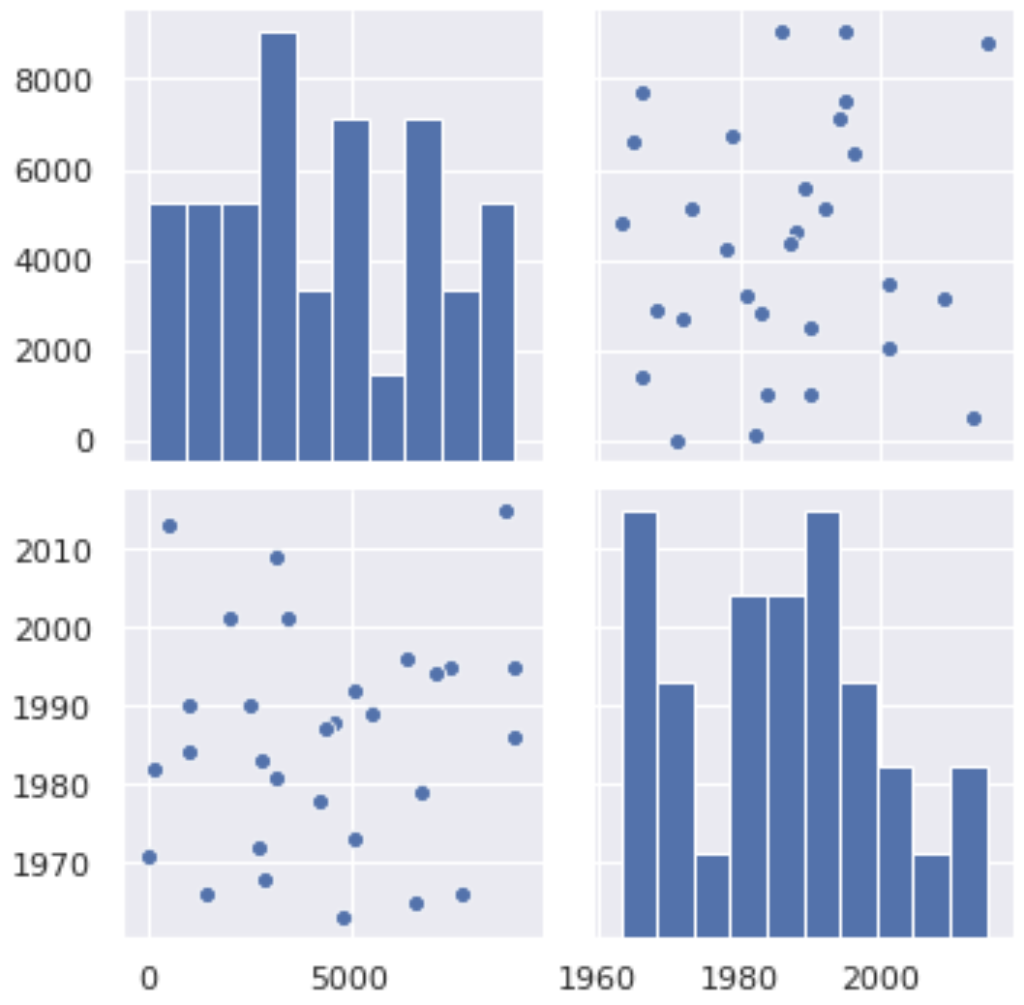
数値部分はグラフや散布図になって見やすくなりました。
sns.pairplot(df)としただけでこんなものが出力される。Seaborn恐るべし。
最後に:Pythonでのデータ分析ではまずこのライブラリをおさえる
データ分析を行う場合には、今回紹介したような超便利ライブラリをしっかりおさえておくことが重要です。
習得には時間がかかりますが、費やした時間相応のものは得られると思いますので興味がある方は習得を目指してみてください。
僕も現在勉強中です。